Requirements for Implementation of a Data Lake in AWS
This post discusses the most common requirements of a data lake. Each section details the requirements followed by the technical implementation. If you are only interested in a particular requirement, directly jump to that section. An introductory read is [1] Benefits and concrete use cases of data lakes are discussed in [2].
Essential services to build a data lake in AWS include:
AWS Simple Storage Service (S3) for storage
AWS Glue for the data catalogs, extract, transform, load (ETL) jobs, etc.
Amazon Athena, the SQL query interface to the lake
AWS Lake Formation, a management layer on top of it all with additional security features

Figure 1: Core services to build a data lake in AWS
Note: The requirements discussed are implemented using the above four services only. Special requirements (virtual private cloud (VPC) networking, custom key encryption, etc.), data ingestion services (RDS, Aurora, DynamoDB, Kinesis, etc.), and data analytics services (Redshift, QuickSight, etc.) are not covered.
Building a data lake starts with a planning phase – how to organize the data to support a business flow.
The common activities to deliver a data lake are managing storage, designing data import and transformation processes as well as building data models. From a compliance viewpoint, data access needs to be granted differently to distinctive stakeholders, system change events need to be audited, and metadata should be attached for discoverability and better understanding.
1. Planning a Data Lake
Before getting started, it is good practice to plan the different zones of a data lake. Usually, they reflect the different stages in the life of data, see figure 2.

Figure 2: Data lake with zones of progressively processed data
All zones of the lake are queryable. The difference is only in the amount of data retained and processed, who has access to which data, and how efficiently the data is organized. The Raw zone could be the landing zone with raw, unprocessed data. (The actual landing zone could be prior to that, a transient storage external to the lake). The Processed area is home to more refined data, with normalized and standardized data types, compressed and transformed to optimal formats (Parquet, OCR). The Published area contains further refinements and additional data generated from the processed data, such as yearly aggregates in business reports and protected personally identifiable information (PII) removed.
The number and nature of zones could vary, of course, for different organizations. However, defining them upfront makes it easier to manage the data lake.
2. Allocation of Storage
S3 is the actual location of all data in a lake [3]. S3 has a myriad of features that are worth knowing by itself. To build a data lake, one must first create a bucket for each zone. The S3 bucket names must be globally unique, i.e., no two buckets across all AWS accounts in all regions can have the same name (just like Internet domain names). Buckets could be named:
mycompany_dl_raw
mycompany_dl_processed
mycompany_dl_published
These buckets will be the root location of all data in the respective zones.
To use the features of AWS Lake Formation (e.g., fine-grained table permissions), one must first register the S3 paths. In the Lake Formation console, under Register and ingest / Data lake locations, click Register location and select the previously created buckets. Accept the suggested default identity and access management (IAM) role (AWSServiceRoleForLakeFormationDataAccess). All folders under the registered S3 paths are thus registered.
The registered buckets must have read/write permissions in IAM for authorized users and roles that produce and consume data.
As a privileged administrative user (or the data lake administrator, see sec. 6), log into the console of Lake Formation, under Permissions / Data locations, click Grant: in the popup window select the storage location and the IAM user or role that is granted access. The instructions in [4] show how to create a role with the permissions of Glue and LakeFormation that can be passed on to another role (e.g., LakeFormationWorkflowRole which used by automated workflows). This allows ETL workflows — see section 4 — to write new data to the registered locations.
3. Creating Databases and Tables
Just like in a traditional database, a data lake is made up of tables. Tables are further grouped into logical databases. The tables of a data lakes have table definition that is schema-on-read. Traditional databases are schema-on-write. Databases and tables together make up the data catalog, which is managed in AWS Glue. The catalog is also accessible from AWS Lake Formation.
Creating a database is as easy as coming up with a descriptive and unique name. Creating a table means choosing a name, selecting a database, choosing a data location (and format), and composing a schema definition that fits the files in the data location. Tables can be created manually or by running an AWS Glue crawler on a data location. A crawler combs through the folders of the S3 path and tries to come up with a sensible table definition. It uses artificial intelligence (AI)/machine learning (ML).
3.1. Populating Tables
Tables are populated by creating files in S3 that fit the schema definition of the table. The S3 buckets can be in the local account, or they can belong to another account.
Examples of processes that output files to S3 buckets are web crawlers, daily batch jobs, EMR/Spark pipelines, among many others.
To illustrate how easy it is to define a table, given a schema and a data location, the following steps show how easy it is to create a table by pointing to an S3 location. The following steps create a table with Amazon product reviews.
In the AWS Lake Formation console, select Data catalog / Tables and click Create table
Enter amazon_reviews for name and chose a database (default)
Under Data store, choose Specified in another account
Under Include path enter s3://amazon-reviews-pds/parquet/
Under Data format, choose PARQUET
Under Schema: click Upload Schema, enter the following text and hit Upload
[ { “Name”: “marketplace”, “Type”: “string” }, { “Name”: “customer_id”, “Type”: “string” }, { “Name”: “review_id”, “Type”: “string” }, { “Name”: “product_id”, “Type”: “string” }, { “Name”: “product_parent”, “Type”: “string” }, { “Name”: “product_title”, “Type”: “string” }, { “Name”: “star_rating”, “Type”: “int” }, { “Name”: “helpful_votes”, “Type”: “int” }, { “Name”: “total_votes”, “Type”: “int” }, { “Name”: “vine”, “Type”: “string” }, { “Name”: “verified_purchase”, “Type”: “string” }, { “Name”: “review_headline”, “Type”: “string” }, { “Name”: “review_body”, “Type”: “string” }, { “Name”: “review_date”, “Type”: “bigint” }, { “Name”: “year”, “Type”: “int” }]Add an extra column named product_category of type string and mark the checkbox labeled Partition Key
Next, the partitions need to be loaded into the meta data store in Glue, or else the table would appear to have zero rows. Switch to the Athena query console, select the default database and run > MSCK REPAIR TABLE amazon_reviews;
Preview the table with > SELECT * FROM “default”.”amazon_reviews” limit 10;
This concludes the steps for defining a table with 160 million rows of product reviews.
Tables can also be populated by streaming services, e.g., any of the Amazon Kinesis services [6] or Amazon MSK (Managed Kafka service) [7].
Table data ingestion from databases, relational and noSQL, is very common (see section 4.1).
4. Workflows for Data Ingestion and ETL
Workflows are a series of jobs to either import data from elsewhere or to transform data in the lake, e.g., from the Raw to the Processed stage.
4.1. Importing Data from Databases
It is very common to replicate the data in operational databases to a central data warehouse for analytics. AWS has the necessary tools to set up periodic data replication pipelines from hosted databases (RDS, Aurora, Redshift, DocumentDB), Mongo, Kafka, or any JDBC connection to the data lake. The steps are as follows:
Create a connection in AWS Glue:
Under Data Catalog/Databases/Connections, set up a database connector (type, driver, host, port, database name, username, password) plus network (VPC) and security (security group) configuration. Test connectivity immediately. If the database is in a private VPC, its security group must allow inbound connections on the database port.
In the Lake Formation console under Register and ingest / Blueprints, click Use blueprint. Select Database snapshot, chose a database connection for the source. If you don’t want the entire database, enter a Source data path argument //to select only certain schema/tables (wildcard %).
Specify the target database, storage location, and output file format (Parquet) under Import target fields.
Start the Glue ETL workflow. The status will indicate discovery phase, then importing phase.
The data import workflows are based on so-called blueprints. AWS Lake Formation offers blueprints for database bulk loads, incremental loads, import of AWS CloudTrail logs, and for the logs from load balancers, see figure 3.

Figure 3: Out-of-box blueprints for building data pipelines to data lake
In the console of Lake Formation, you have full observability of each blueprint-based workflow: time of last execution, success status, logs, even a flow diagram. A workflow can run incrementally on new data. It can run on demand or periodically on a schedule.
4.2. ETL Workflows
Data needs to be cleaned up, normalized, categorized, right-sized, etc. Often, data streams need to be joined together to build profiles. The list of use cases for ETL processing is endless.
The solution is found in AWS Glue under Workflows. A workflow is an orchestration of Triggers, Crawlers and Jobs. Triggers start, stop, schedule, or integrate a workflow with the outside environment. Crawlers are the AWS Glue crawlers that infer a table definition by ‘crawling’ over some data destination (S3 path, JDBC connection, etc.). Jobs are the actual ETL jobs that process and transform data. Glue jobs can be authored visually in AWS Glue Studio (drag-and-drop data sources and map fields visually), written by hand in PySpark or Python script, or developed interactively on Jupyter notebooks (Glue Dev endpoints). Glue jobs run on Spark clusters. All AWS Glue services are serverless, i.e., they have a pay-as-you-go cost structure and no hardware to manage.
5. Logging for Compliance
A data repository with sensitive information may be subject to auditing for regulatory compliance. Who did what and when, who gave permission to access the data, etc.?
AWS Lake Formation is integrated with AWS CloudTrail by default. There is a trail of all actions taken by a user, a security role or service. Using the information collected by CloudTrail, you can determine the request that was made to Lake Formation, the IP address from which the request was made, who made the request, when it was made, and additional details. The cloud trail can be saved to an S3 bucket for retention. Dashboards can be built with cloud trail records.
6. Access Control for Compliance
A data lake with sensitive information needs controls to restrict access to unauthorized staff. Users with different responsibilities and roles should see different parts of the data. Is it possible to protect tables, rows, and columns from being accessed?
In AWS, the answer is yes. AWS Lake Formation provides a permissions model that is based on a simple grant/revoke mechanism, in addition to the IAM permissions.
To simplify, data lake access control management can be delegated to a Lake Formation (LF) Administrator, an IAM user with full permissions starting with lakeformation, s3, glue, tag, cloudtrail, or a site-wide administrator. The LF Administrator can grant/revoke permissions to all assets of the lake.
As a best practice, data lake permissions are assigned to IAM roles which are then assigned to groups or users. A permission should never be assigned to individual users. Working with IAM roles provides a layer of abstraction and reduces the administrative work.
6.1. Granting data access permissions
In the AWS Lake Formation console, the Lake Administrator selects Permissions/Data lake permissions and clicks Grant. A screen pops up which allows granting access to principals (IAM users, roles, SAML users and groups, or external accounts). The data can be defined by tags (LF-Tags) or as Named data catalog resources (database, table). The permissions are grouped into database permissions (Create table, Alter, Drop, Describe) and table permissions (Select, Insert, Delete, Alter, Describe, Drop), see figure 4.

Figure 4: Data access grant page
6.2. LF-Tag Based Permissions
Can the access to data resources (database, table, columns) be managed in an abstract way?
With AWS Lake Formation, it can, with LF-Tags. LF-Tags can be modeled as an ontology of data attributes. See figure 5, e.g., a classification of data into confidential, sensitive, and non-confidential. The LF-tags are then assigned to catalog resources as well as to principals.
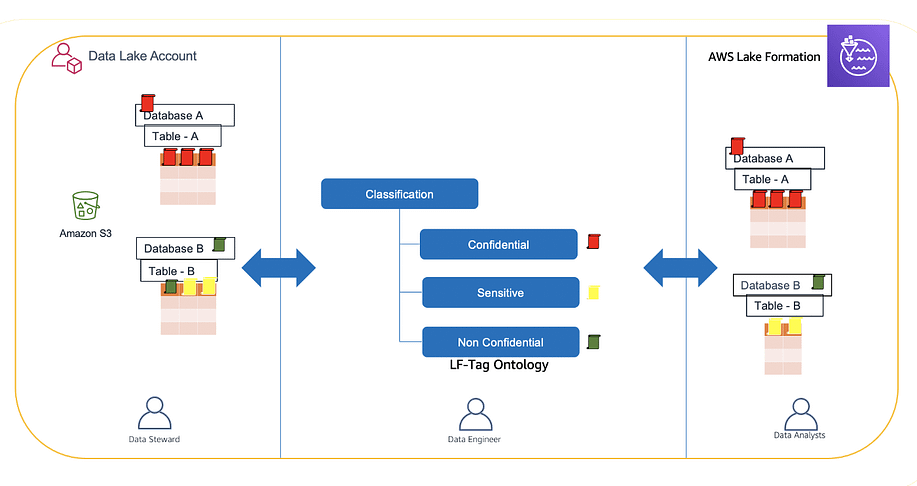
Figure 5: LF-Tag ontology mapping permissions between catalog resources and principals (users)
Only principals that are granted matching LF-tags can access the resources. LF-tags also reduce the number of grant operations to m+n, from m*n
if you have m resources and n principals. The overhead of LF-tags pays off if you have 3 or more resources to manage.
Working with LF-tag based permissions allows for maximum separation of concerns between team members and therefore adherence to strict security standards: e.g., a chief information officer (CIO) can define the ontology of LF-tags, a data engineer can assign the tags to various catalog resources and IAM roles, while a human resources’ (HR) application for employee onboarding creates IAM accounts (or single sign-on (SSO) principals) in specific groups with access to said IAM roles.
7. Meta Data and Discoverability
Data catalog resources (databases, tables, columns) often need to be grouped by who created them, what purpose they serve, their useful time-of-life, cost center, department, environment, etc. Those values can be added as custom properties on the table properties page, see figure 6.

Figure 6: Adding custom properties for environment and department to a table
Tables can then be searched by their property values (case sensitive search) on the Tables page in AWS Glue or AWS Lake Formation.
For a large data lake with hundreds of tables, making your data discoverable by metadata is not only convenient, but also necessary for effective data management.
8. Summary
This post discussed common requirements for building a data lake and how to achieve those in AWS. The focus was on planning and organization, database creation, data import, ETL workflow basics, data access control, logging, and meta data.
More time and attention will be given to these topics in future posts:
Methods to import data (Kinesis, sFTP, etc.)
Ways to consume the data of a lake (Athena, Data API, Redshift Spectrum, Python libraries, etc.)
Governed tables in AWS data lakes
Hopefully, this post was educational enough to give enough insight into AWS data lakes without having to read the full documentation.
__________
References & Related Links:
[1] Data Lakes Explained
[2] Benefits and Use Cases of a Data Lake
[3] https://docs.aws.amazon.com/s3/
[4] https://docs.aws.amazon.com/lake-formation/latest/dg/getting-started-setup.html#iam-create-blueprint-role
[5] https://aws.amazon.com/lake-formation
[6] https://console.aws.amazon.com/kinesis
[7] https://console.aws.amazon.com/msk
[8] https://docs.aws.amazon.com/lake-formation/latest/dg/what-is-lake-formation.htm

Stefan Deusch
Forward-thinking Engineering leader offering 20 years of experience with a background in effective and dynamic work environments. Clear communicator, decision-maker, and problem solver focused on achieving project objectives with speed and accuracy. I am passionate about building quality teams, cloud computing, and machine learning.


